En nuestros cursos online no solo enseñamos teoría, sino que trabajamos con proyectos reales, aplicables al mundo laboral. Esta página muestra uno de esos proyectos prácticos: la transcripción automática de audios con Python e Inteligencia Artificial.
A través de unas pocas líneas de código, aprenderás a:
Este proyecto forma parte del contenido aplicado de nuestros cursos de:
👉 Es una muestra real de lo que podrás hacer al formarte con nosotros. Todo el código está explicado paso a paso, y podrás reutilizarlo y adaptarlo para tareas personales, académicas o profesionales.
Uno de los usos más valiosos de la Inteligencia Artificial aplicada a la programación es la automatización de tareas tediosas o repetitivas, como la transcripción de audios. Poder convertir una grabación de voz en texto de forma automática abre muchas posibilidades en distintos sectores profesionales, académicos y personales.
Por ejemplo, en el ámbito educativo, permite a docentes y estudiantes registrar clases o charlas con fines de estudio. En contextos corporativos, es útil para generar actas de reuniones de forma automática. En investigación cualitativa, facilita el análisis de entrevistas. En el mundo del periodismo, permite obtener versiones escritas de entrevistas o conferencias de prensa sin transcribir manualmente. En el ambito de la IA avanzada se utiliza para captar la personalidad de una persona.
Entre las aplicaciones destacadas podemos mencionar:
En este proyecto vamos a mostrar cómo, con unas pocas líneas de Python, podemos lograr nuestro objetivo gracias al servicio de AssemblyAI, que nos permite subir un archivo de audio y obtener la transcripción con diarización de hablantes (es decir, identifica quién habla en cada momento).
¿Qué es AssemblyAI?
AssemblyAI es una plataforma de transcripción automática de audio basada en modelos de Inteligencia Artificial de última generación. Permite enviar audios a través de una API REST y obtener su contenido en texto, con la opción de incluir funciones como diarización (identificación de hablantes), detección de temas, puntuación automática, y más.
Asegurate de tener Python 3.8 o superior instalado y ejecutandose. En Windows, podés instalar Python 3.8 aparte en una carpeta distinta, como C:\Python38 o la unidad y nombre de carpeta que prefieras .
Luego instalá la librería necesaria con la siguiente instrucción:
C:\Python38\python.exe -m pip install requestsGuardá este código en un archivo llamado transcribir.py. A continuación se explica cada parte, paso a paso, dentro del código mediante comentarios:
import requests
import time
API_KEY = 'TU_API_KEY'
# Ingresa la APi KEY que provee AssemblyAI.
FILENAME = 'COLOCA NOMBRE DEL ARCHIVO A SUBIR , POR EJEMPLO voz029.mp3'
headers = {'authorization': API_KEY}
# Subir archivo
# Esta función se encarga de subir el archivo de audio a los servidores de AssemblyAI.
# Devuelve una URL que se usará luego para solicitar la transcripción.
def upload_file(filename):
with open(filename, 'rb') as f:
response = requests.post(
'https://api.assemblyai.com/v2/upload',
headers=headers,
files={'file': f}
)
response.raise_for_status()
return response.json()['upload_url']
print("Subiendo archivo...")
audio_url = upload_file(FILENAME)
print("Archivo subido. URL:", audio_url)
# Pedir transcripción
# Con la URL del archivo subido, le pedimos a AssemblyAI que lo transcriba.
# También activamos la opción speaker_labels para que detecte los distintos hablantes.
transcription_request = {
"audio_url": audio_url,
"speaker_labels": True,
"language_code": "es"
}
print("Solicitando transcripción...")
response = requests.post(
"https://api.assemblyai.com/v2/transcript",
json=transcription_request,
headers=headers
)
response.raise_for_status()
transcript_id = response.json()['id']
print("ID de transcripción:", transcript_id)
# Esperar resultado
# La transcripción puede tardar unos minutos, por lo que preguntamos periódicamente el estado.
# Cuando el estado es 'completed', accedemos a los datos.
print("Esperando transcripción...")
while True:
polling_response = requests.get(
f"https://api.assemblyai.com/v2/transcript/{transcript_id}",
headers=headers
)
result = polling_response.json()
if result['status'] == 'completed':
break
elif result['status'] == 'error':
print("❌ Error:", result['error'])
exit(1)
time.sleep(10)
# Mostrar y guardar transcripción
# Una vez completada la transcripción, mostramos por pantalla los fragmentos por hablante
# y también los escribimos en un archivo de texto llamado 'transcripcion.txt'.
with open("transcripcion.txt", "w", encoding="utf-8") as f:
for segmento in result['utterances']:
linea = f"Hablante {segmento['speaker']}: {segmento['text']}\n"
print(f"\n🔊 {linea.strip()}")
f.write(linea)
print("✅ Transcripción guardada como 'transcripcion.txt'")
Una vez que hayas guardado el archivo transcribir.py y tengas el archivo de audio en la misma carpeta , seguí estos pasos:
Win + R, escribí cmd, y presioná Enter.cd C:\Users\TuNombre\Documents\proyectos\transcripcionpython transcribir.pyC:\Python38\python.exe transcribir.pyEsto iniciará todo el proceso:
transcripcion.txt con el resultado finalError común: Transcoding failed. File does not appear to contain audio.
Esto ocurre cuando el archivo, aunque tenga extensión .m4a, .mp3 u otra, no tiene una codificación válida. La solución más sencilla es convertir el archivo a otro formato de audio:
.mp3 o .wav.La calidad del audio afecta directamente la transcripción. Algunos problemas comunes:
La diarización permite identificar quién habla en cada momento, sin ella el texto sería continuo o texto plano. :
Hablante 0: Buenas tardes, vamos a comenzar.
Hablante 1: Perfecto, ya estamos todos.
Hablante 0: La idea de hoy es revisar los puntos del informe.
Sin esta función, el texto sería plano o continuo y difícil de interpretar.
Aplicar el script de transcripción desarrollado en esta lección para convertir una entrevista con múltiples hablantes en un texto estructurado que identifique claramente a cada persona que interviene.
Se utilizará una grabación real con dos voces claramente diferenciadas: Marina (entrevistadora) y Pilar (entrevistada).
🔗 Descargar audio MP3:
www.notesinspanish.com/2006/08/29/notes-in-spanish-podcast-advanced-42-entrevista-con-pilar/
Consejo: Guardá el archivo como entrevista_pilar.mp3 en la misma carpeta que tu script transcribir.py.
transcripcion.txt con el contenido separado por hablante:Hablante 0: Hola Pilar, bienvenida.
Hablante 1: Muchas gracias, encantada de estar aquí.
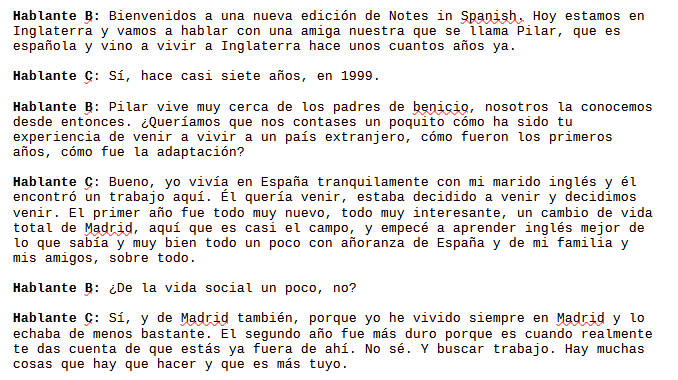
...El script generará un archivo llamado transcripcion.txt con la transcripción completa separada por hablantes, útil para:
A continuación vemos una captura del resultado esperado una vez realizada la transcripción del audio (solo el comienzo de 3 páginas de dialogo):
Hasta ahora, en la entrevista con Pilar, vimos cómo es posible transcribir automáticamente una conversación, e incluso identificar qué persona habló en cada momento. Sin embargo, la IA nos permite ir aún más lejos:
Existen modelos avanzados de IA capaces de analizar cómo se dice algo y no solo lo que se dice. A esto se le conoce como Speech Emotion Recognition (SER). Algunas emociones que se pueden detectar automáticamente incluyen:
El sistema analiza aspectos como el tono de voz, la velocidad al hablar, las pausas, la intensidad y las curvas melódicas de cada intervención.
torchaudio o pyAudioAnalysis.Hablante 0 (neutral): Hola Pilar, bienvenida.
Hablante 1 (alegre): Gracias, estoy encantada de estar aquí.
Hablante 0 (dudoso): Bien... ¿empezamos?Este tipo de análisis es muy valioso en:
Este análisis emocional es un paso más avanzado, pero demuestra el enorme potencial que tiene la IA para comprender no solo el contenido, sino también el contexto y la intención emocional de una conversación.
Este proyecto muestra cómo con pocas líneas de código y una API gratuita se puede aplicar Inteligencia Artificial para resolver tareas reales. Es un excelente ejemplo de la intersección entre programación, herramientas online y procesamiento de lenguaje natural, útil en educación, periodismo, empresas e investigación.
¿Te animás a explorarlo con nosotros? Este es solo el comienzo de todo lo que podés lograr.
© 2025 Red21.net
Cursos prácticos de Inteligencia Artificial aplicada